
Google BigQuery nedávno představilo novinku v podobě sekce „Overview“. Tuto funkci si můžeme představit jako rozcestník, který usnadňuje navigaci a celkové ovládání tohoto komplexního datově analytického prostředí.
BigQuery již dávno není pouhou databází či úložištěm pro rychlou práci s velkými daty. Dnes jde o mnohem komplexnější a robustnější nástroj, který pokrývá téměř celý analytický proces – od importu dat až po jejich vizualizaci.
Síla AI v BigQuery
Google v poslední době masivně investuje do infrastruktury a služeb spojených s AI, což se výrazně promítá i do funkcí BigQuery. V tomto prostředí můžete využívat řadu AI agentů, jako jsou Data Insight Agent, Data Science Agent či Data Engineering Agent. S jejich pomocí lze v podstatě vybudovat celý datový sklad včetně datových pipeline (ETL). Praxe však ukazuje, že u složitějších úloh bude od uživatelů stále vyžadována trpělivost a od Googlu další investice. Přesto již dnes jasně vidíme směr, kterým se datová analytika a business intelligence ubírají.
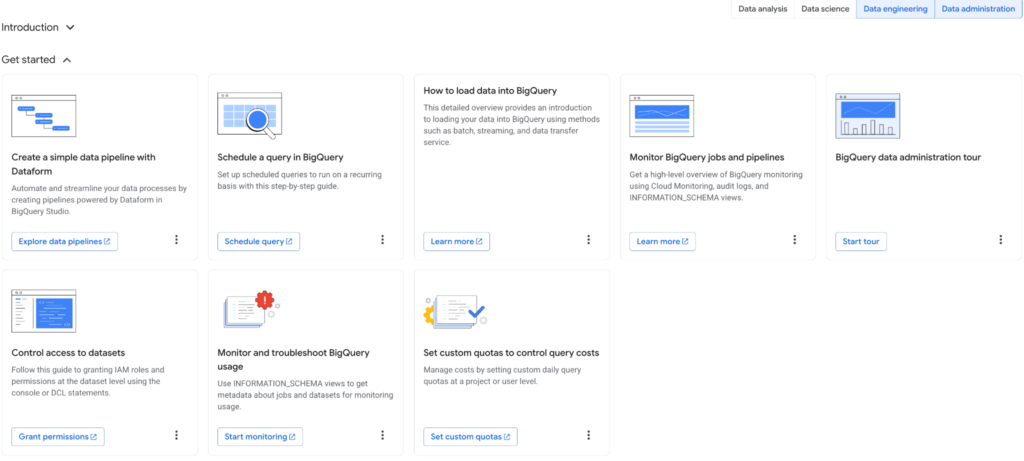
V rámci „Overview“ máte možnost nahlížet na BigQuery ze čtyř perspektiv:
- Datová analýza
- Data Science
- Data Engineering
- Administrace dat
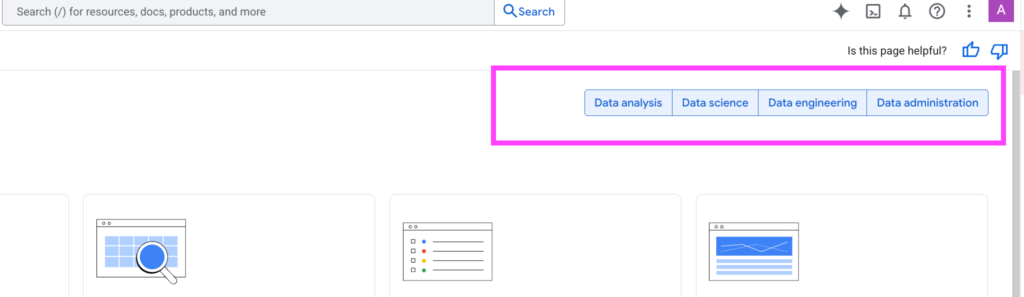
Jednotlivé sekce lze filtrovat (zapínat a vypínat), čímž se přizpůsobuje zobrazený obsah. Nejde jen o přehled funkcí, které BQ nabízí, ale především o chytrou navigaci napříč rozsáhlou dokumentací, což výrazně usnadňuje cílené vyhledávání konkrétních témat.
Datová analýza a Data Science
Začátečníci ocení funkci „tour“ – sérii tutoriálů integrovaných přímo v platformě. Tyto návody jsou zaměřeny na konkrétní úkoly: jak nahrát první data, vytvořit vizualizaci nebo pracovat s veřejnými datasety. Tato funkce výrazně urychluje orientaci a seznámení s platformou.
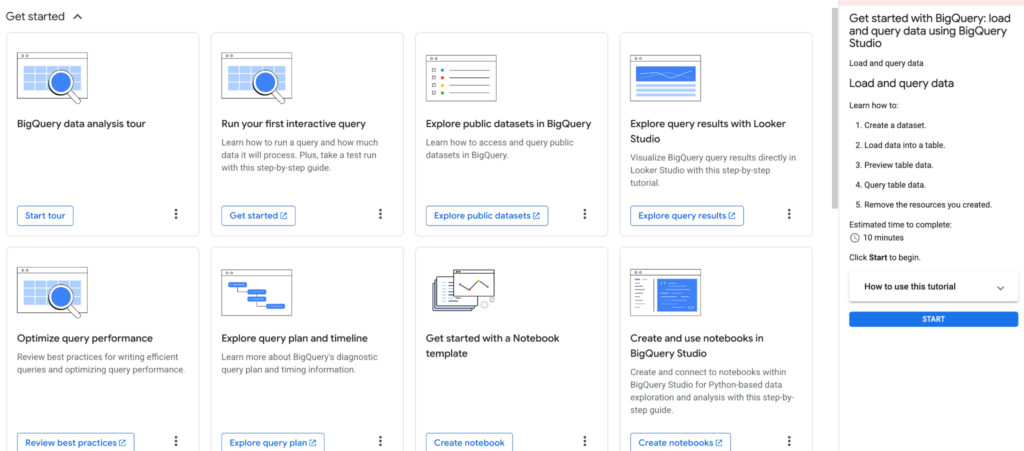
BigQuery nabízí mnoho způsobů zpracování dat. Můžete jednoduše nahrát soubory z Google Sheets či formáty jako CSV a následně nad nimi provádět dotazy. Pro pokročilejší práci jsou k dispozici například BigQuery Notebooks.
Demokratizace technologií díky AI
Díky úzkému propojení s Vertex AI lze přímo v prostředí BQ (a dokonce pomocí SQL) vytvářet a volat ML modely. Není k tomu potřeba hluboká znalost MLOps; stačí základy SQL a dokumentace. Tento přístup demokratizuje pokročilé technologie a zpřístupňuje je širšímu okruhu uživatelů. Navíc dnes značnou část kódu dokáže vygenerovat samotný jazykový model.
Příkladem je generování SQL dotazů pomocí přirozeného jazyka. Prompt by měl být věcný a výstižný, bez zbytečných složitostí (podrobněji se tomuto tématu budu věnovat v článku plánovaném na leden 2026). Vestavěný model navrhne konkrétní query, kterou můžete vložit do editoru nebo dále ladit pomocí funkce „refine“. Pro kontrolu lze využít i funkci „query summary“.
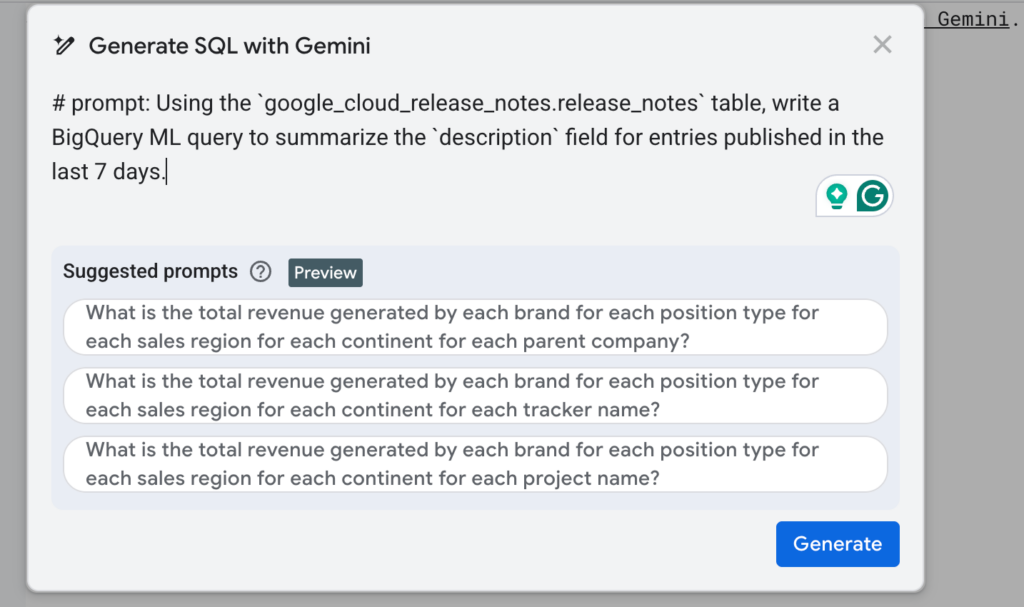
Tento trend je jasný: analytici a datoví vědci již nebudou muset psát veškerý kód „od nuly“ (from scratch). Je to skutečný „game changer“, který otevírá svět AI a ML i byznysovým uživatelům a postupně stírá rozdíly mezi technickými a netechnickými pozicemi.
-- # prompt: Using the `google_cloud_release_notes.release_notes` table, write a BigQuery ML query to summarize the `description` field for entries published in the last 7 days.
SELECT
ml_generate_text_result.ml_generate_text_result AS summary
FROM
ML.GENERATE_TEXT( MODEL `cloud-ai-platform.generative_models.gemini-pro`,
(
SELECT
description
FROM
`bigquery-public-data.google_cloud_release_notes.release_notes`
WHERE
as_of_daily >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) ),
STRUCT( 0.2 AS temperature,
100 AS max_output_tokens ) )
Pro pokročilé uživatele
Zkušení uživatelé mohou v BigQuery detailně sledovat průběh dotazů a spotřebu prostředků, což je klíčové pro optimalizaci pipelines a nákladů (FinOps). BQ nabízí různé modely nacenění a dokumentace obsahuje podrobné postupy pro optimalizaci dotazů. Vzhledem k tomu, že je BQ sloupcově orientovaná databáze, je zásadní umět pracovat s partitioningem či clusteringem, aby se minimalizoval objem procházených dat.
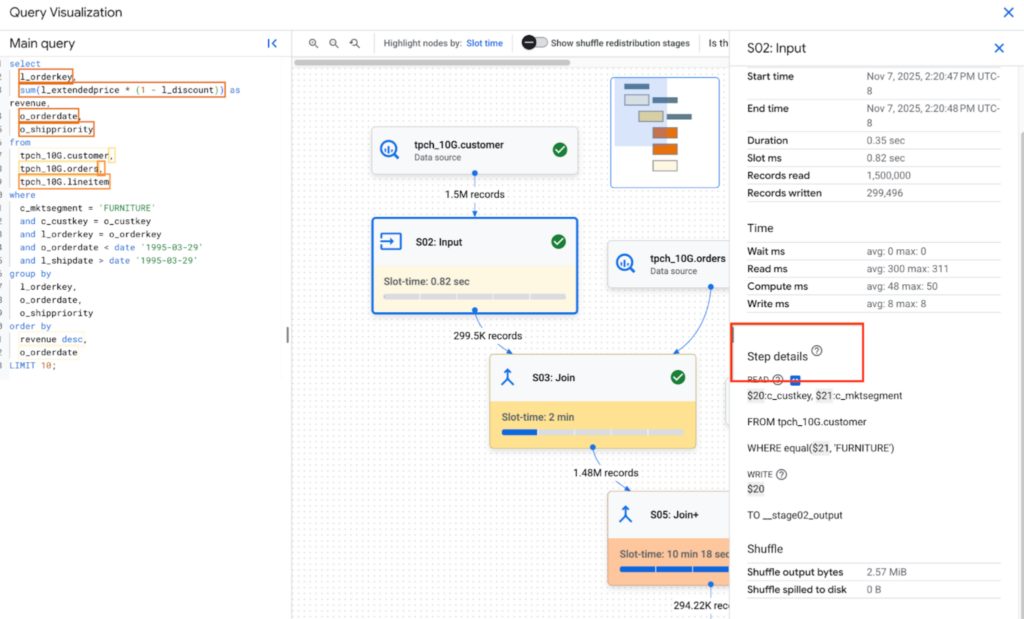
Data Engineering a Administrace
Tato část se zaměřuje na technickou stránku: od ukládání a transformace dat přes scheduling (plánování) až po monitoring nákladů a řešení chyb v pipelines.
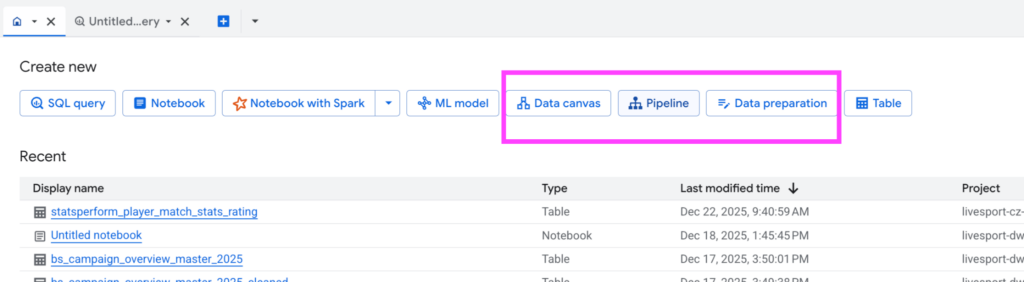
Klíčovým nástrojem je DataForm – orchestrační funkce pro řízení datových pipelines přímo v BQ. Google jej koupil v roce 2020 a po plné integraci dnes slouží jako plnohodnotná služba. Pipelines se zde píší v SQL s konfigurační částí v JavaScriptu. V rámci BQ Studia lze navíc využít low-code/no-code nástroje jako Data Canvas a Data Pipelines.
I když AI agenti pomáhají s jednoduššími úkoly, u komplexních architektur je stále jistější spoléhat na vlastní skripty (byť s pomocí AI při jejich generování). Kompletní kontrolu nad ETL procesy zatím agentům svěřit nelze.
FinOps a správa oprávnění
V oblasti monitoringu nákladů je základem edukace uživatelů. Je důležité vědět, že v BQ se nevyplácí používat SELECT * a že databáze preferuje denormalizovanou strukturu (na rozdíl od tradičních relačních databází pracujících s 3NF až 5NF). BQ také umožňuje nastavit capping – limity (kredity) na dotazy či určité období.
Správa oprávnění (Permissions) umožňuje detailní nastavení přístupů od úrovně funkcí až po jednotlivé datasety a tabulky. Jde o komplexní disciplínu, kde se chyby mohou vymstít, proto je potřeba postupovat obezřetně (i když i zde lze některé postupy konzultovat s AI modelem).
Na závěr stojí za zmínku Analytics Hub, který umožňuje bezpečné sdílení dat v rámci organizace i mimo ni, což otevírá dveře k jejich případné monetizaci.

Napsat komentář